Flink学习-第一天-Flink安装
简介
Apache Flink 是一个开源的流处理框架,用于在无边界和有边界的数据流上进行有状态的计算。它能够在各种常见的集群环境中运行,包括 YARN、Mesos 和 Kubernetes,同时也支持独立部署。Flink 设计用于以内存速度和任意规模进行计算,能够处理无界流(无定义结束的数据流)和有界流(有定义开始和结束的数据流)。
Flink的核心特性
- 批流一体化:Flink 提供了统一的 API,使得批处理和流处理可以在同一个框架下进行,简化了开发流程。
- 精确的状态管理:Flink 提供了精细的状态管理能力,允许开发者在流处理中维护和操作状态。
- 事件时间支持:Flink 能够处理基于事件时间的计算,这对于处理乱序事件或者需要基于事件发生时间的计算非常重要。
- 精确一次的状态一致性保障:Flink 通过其检查点(Checkpoint)机制,保证了即使在发生故障的情况下也能保证状态的一致性,并且能够精确一次地更新状态。
Flink的应用场景
Flink 被广泛应用于实时数据处理的场景,例如:
- 实时智能推荐:利用 Flink 流计算实时更新用户行为指标和模型,为用户推荐商品。
- 复杂事件处理:在工业领域,Flink 可以处理大量数据并且对数据的时效性要求较高,如使用 Flink 的 CEP(复杂事件处理)进行事件模式的抽取。
- 实时欺诈检测:在金融领域,Flink 能够在毫秒级完成对欺诈行为的判断,并实时拦截可疑交易。
- 实时数仓与ETL:结合离线数仓,Flink 可以对流式数据进行实时清洗、归并、结构化处理,优化数据仓库的性能。
- 流数据分析:实时计算各类数据指标,并利用实时结果调整在线系统相关策略。
- 实时报表分析:如淘宝双十一实时战报,利用 Flink 实时计算并展示重要指标变化。
Flink与Spark Streaming的比较
- 数据模型:Flink 基于数据流模型,而 Spark Streaming 基于 RDD(弹性分布式数据集)模型。
- 运行时架构:Flink 是标准的流执行模式,可以直接在节点间传递处理结果;而 Spark 是批计算,需要等待一个批次完成后才能计算下一个。
Flink 的这些特性使其成为处理实时数据流的强大工具,尤其是在需要低延迟和高吞吐量的场景中。随着实时数据处理需求的增长,Flink 可能会在未来的数据处理领域扮演更加重要的角色。
单机安装
集群安装环境基于Ubuntu22.04 + Graalvm21
服务器配置
环境搭建
文章中使用的Flink版本为2.1.0
下载graalvm
https://download.oracle.com/graalvm/21/latest/graalvm-jdk-21_linux-x64_bin.tar.gz
附件:
下载Flink
https://dlcdn.apache.org/flink/flink-2.1.0/flink-2.1.0-bin-scala_2.12.tgz
配置flink+java
解压flink和java到指定目录
设置PATH
cat >>/etc/profile<<EOF
PATH=$PATH:/usr/local/sbin/flink/bin:/usr/local/sbin/graalvm21/bin
export PATH
EOF
source /etc/profile
测试命令

启动flink集群
启动jobmanager
# 控制台启动
jobmanager.sh start -D jobmanager.rpc.address=127.0.0.1 -D jobmanager.bind-host=0.0.0.0 -D web.tmpdir=/tmp/flink/files -D web.submit.enable=true -D web.cancel.enable=true -D rest.address=0.0.0.0 -D blob.server.port=6124 -D jobmanager.memory.heap.size=384m -D jobmanager.memory.jvm-metaspace.size=256m -D jobmanager.memory.jvm-overhead.min=16m -D jobmanager.memory.jvm-overhead.max=32m -D jobmanager.memory.off-heap.size=128m -D jobmanager.memory.flink.size=512m -D jobmanager.memory.process.size=800m

启动查看
启动taskmanager
taskmanager.sh start
-D taskmanager.bind-host=0.0.0.0
-D taskmanager.numberOfTaskSlots=12
-D jobmanager.rpc.address=127.0.0.1
-D taskmanager.host=127.0.0.1
-D taskmanager.memory.framework.heap.size=128m
-D taskmanager.memory.task.heap.size=1536m
-D taskmanager.memory.managed.size=0m
-D taskmanager.memory.process.size=2560m
-D taskmanager.memory.jvm-metaspace.size=256m
启动查看
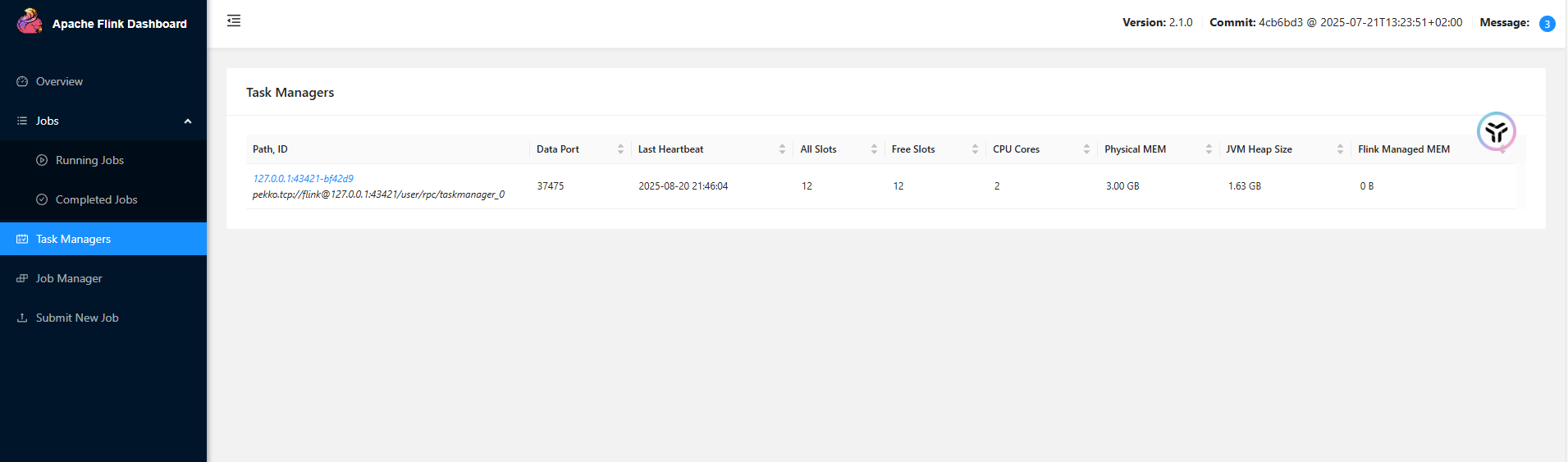
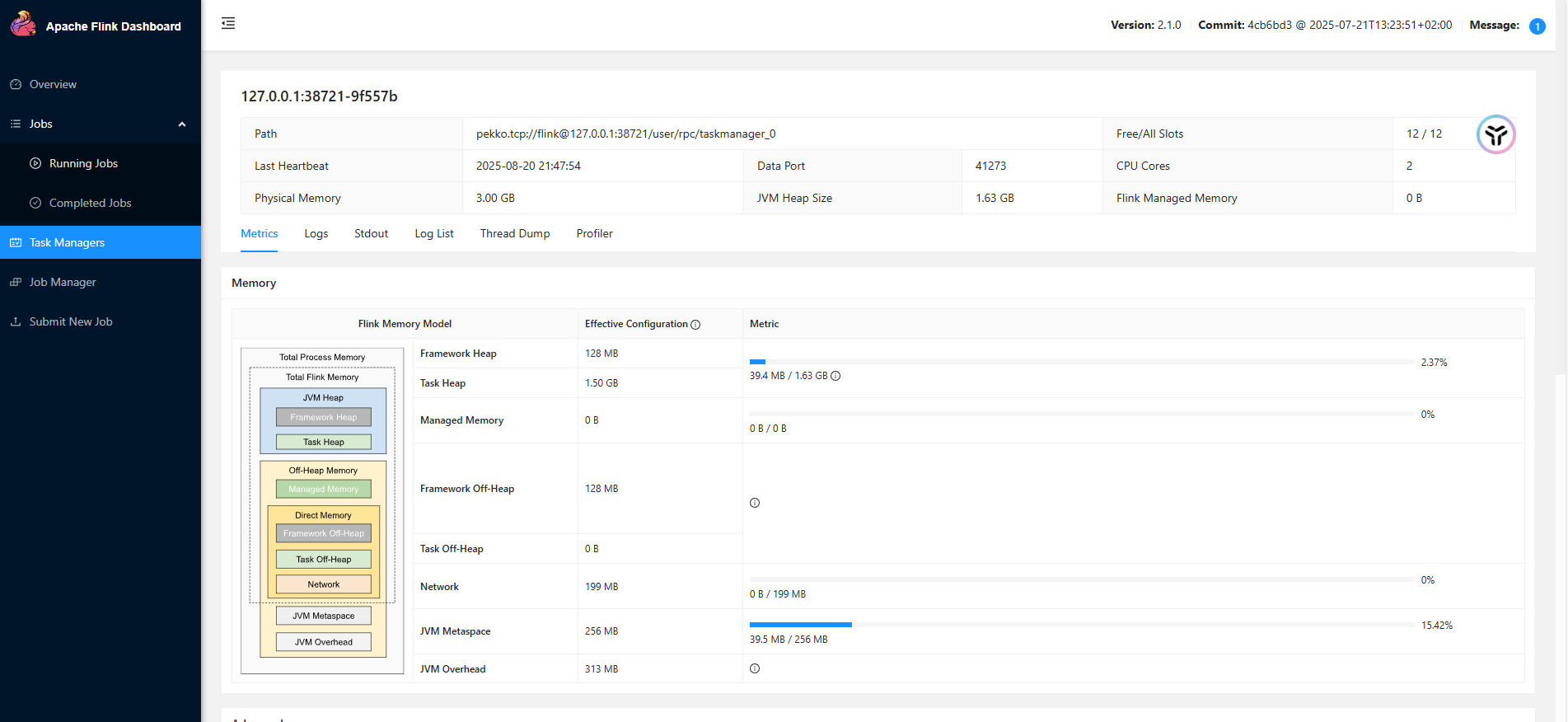
开发第一个程序-WordCount
初始项目为多模块,后续学习都会在这个项目里面创建对应的模块
创建项目
父级项目 pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.lhstack</groupId>
<artifactId>flink-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>pom</packaging>
<modules>
<module>flink-connector-files</module>
</modules>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<logback.version>1.5.18</logback.version>
<flink.version>2.1.0</flink.version>
<slf4j.version>2.0.7</slf4j.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<artifactId>flink-connector-files</artifactId>
<groupId>org.apache.flink</groupId>
<version>${flink.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-file-sink-common</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>${logback.version}</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>aly</id>
<name>aly</name>
<url>https://maven.aliyun.com/repository/public</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>aly</id>
<name>aly</name>
<url>https://maven.aliyun.com/repository/public</url>
</pluginRepository>
</pluginRepositories>
<build>
<plugins>
<plugin>
<artifactId>maven-shade-plugin</artifactId>
<executions>
<execution>
<id>shade</id>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
创建normal-example模块
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.lhstack</groupId>
<artifactId>flink-demo</artifactId>
<version>1.0-SNAPSHOT</version>
</parent>
<artifactId>normal-example</artifactId>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
</project>
开发WordCount项目代码
package com.lhstack.normal;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.stream.Stream;
public class Main {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
String text = "Happiness isn’t just a gift, but a skill that can be learned and cultivated. People always rely on shortcuts like watching television, eating, and shopping to feel happy. But external satisfaction may lead to a sense of emptiness and even depression. Authentic happiness comes from identifying and cultivating people’s strengths like kindness, humor, and generosity";
String[] arrays = text.split(",");
DataStreamSource<String> streamSource = executionEnvironment.fromData(arrays);
streamSource
.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
String[] strings = value.split(" ");
Stream.of(strings).filter(StringUtils::isNotBlank).map(String::trim).forEach(out::collect);
}
})
.map(item -> Tuple2.of(item,1))
.returns(new TypeHint<Tuple2<String, Integer>>() {
})
.keyBy(item -> item.f0)
.sum("f1")
.printToErr().setParallelism(1).name("统计单词数量");
executionEnvironment.execute();
}
}
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 日志输出格式 -->
<property name="log.pattern" value="%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread{10}] %-5level %logger{20} - %msg%n" />
<!-- 控制台输出 -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>${log.pattern}</pattern>
</encoder>
</appender>
<!-- 系统模块日志级别控制 -->
<logger name="org.apache.flink" level="error" />
<root level="info">
<appender-ref ref="console" />
</root>
</configuration>
通过idea启动
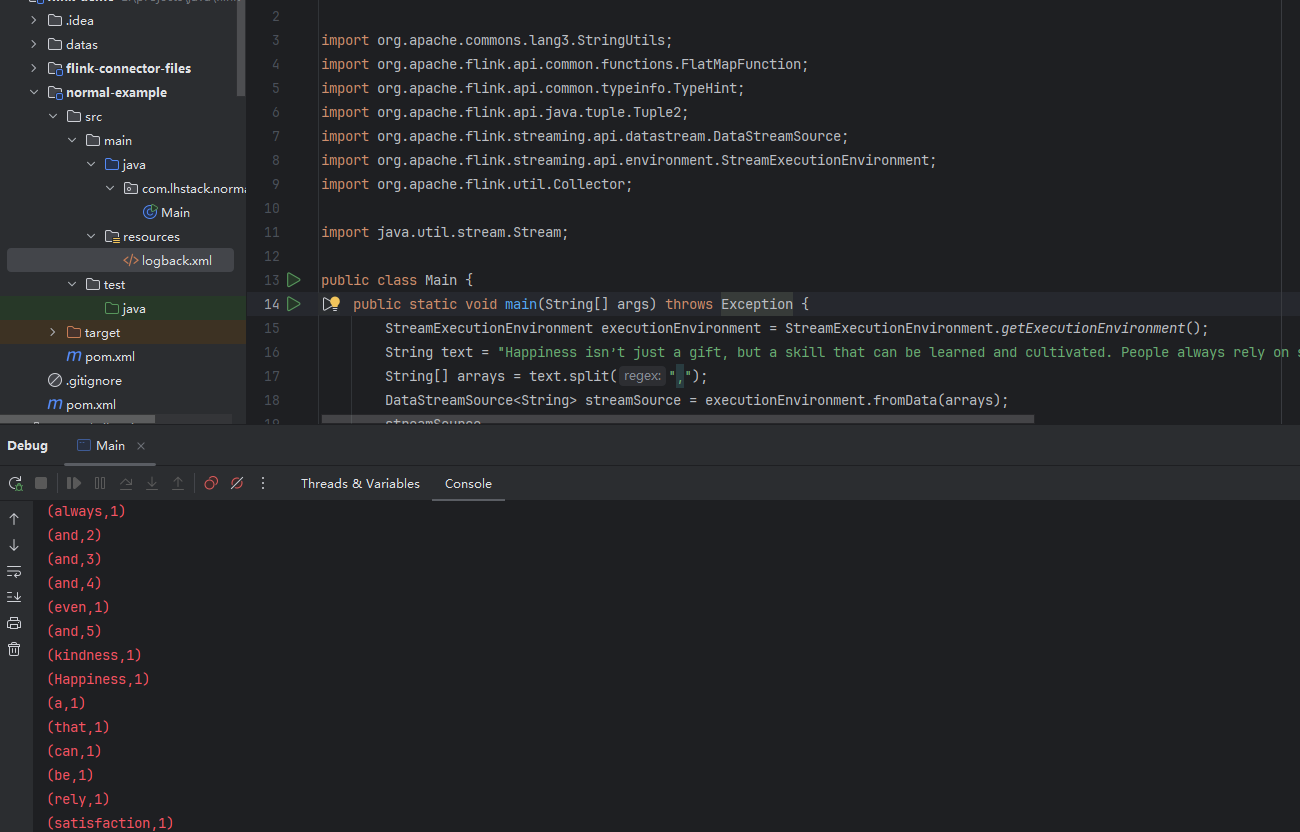
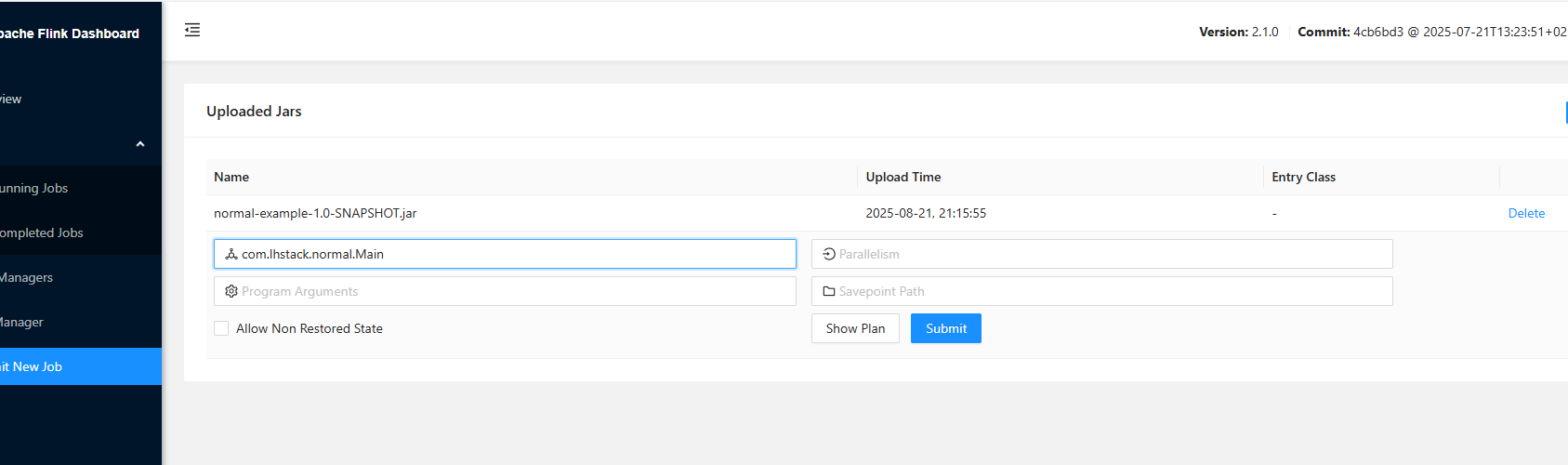
打包上传到flink执行
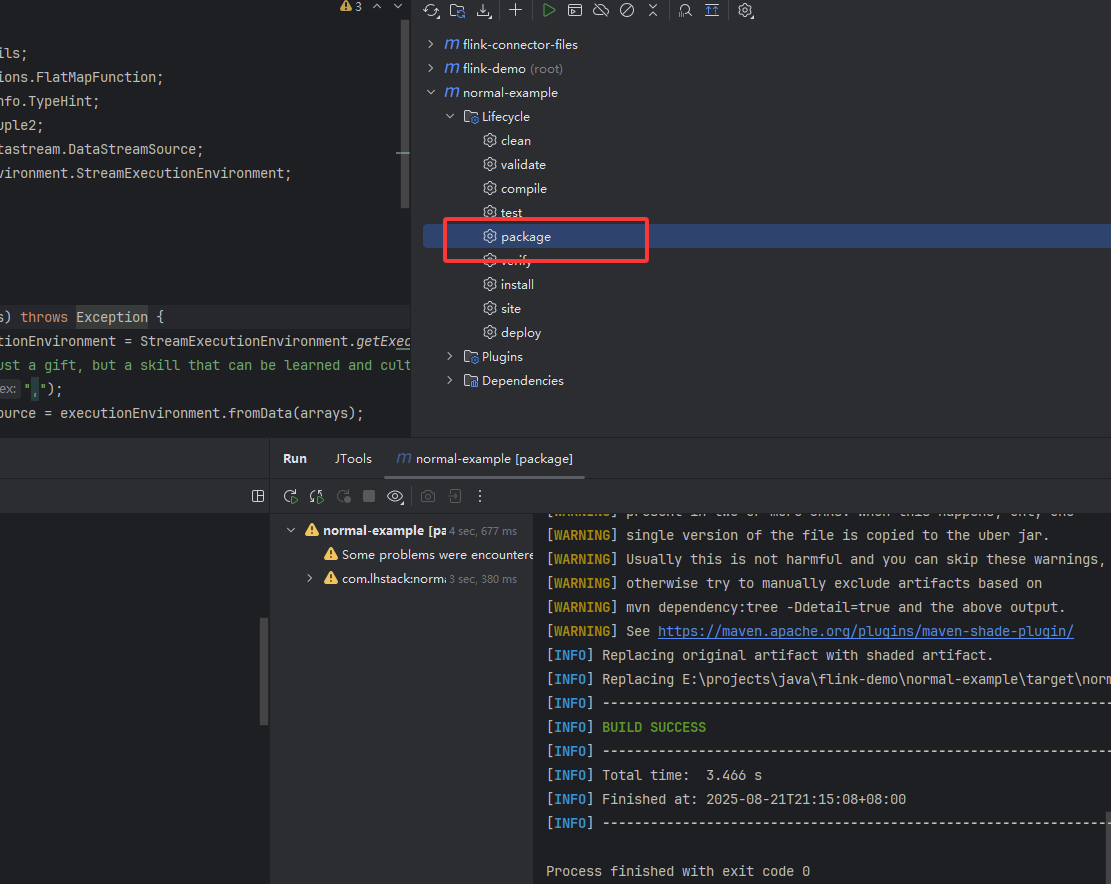
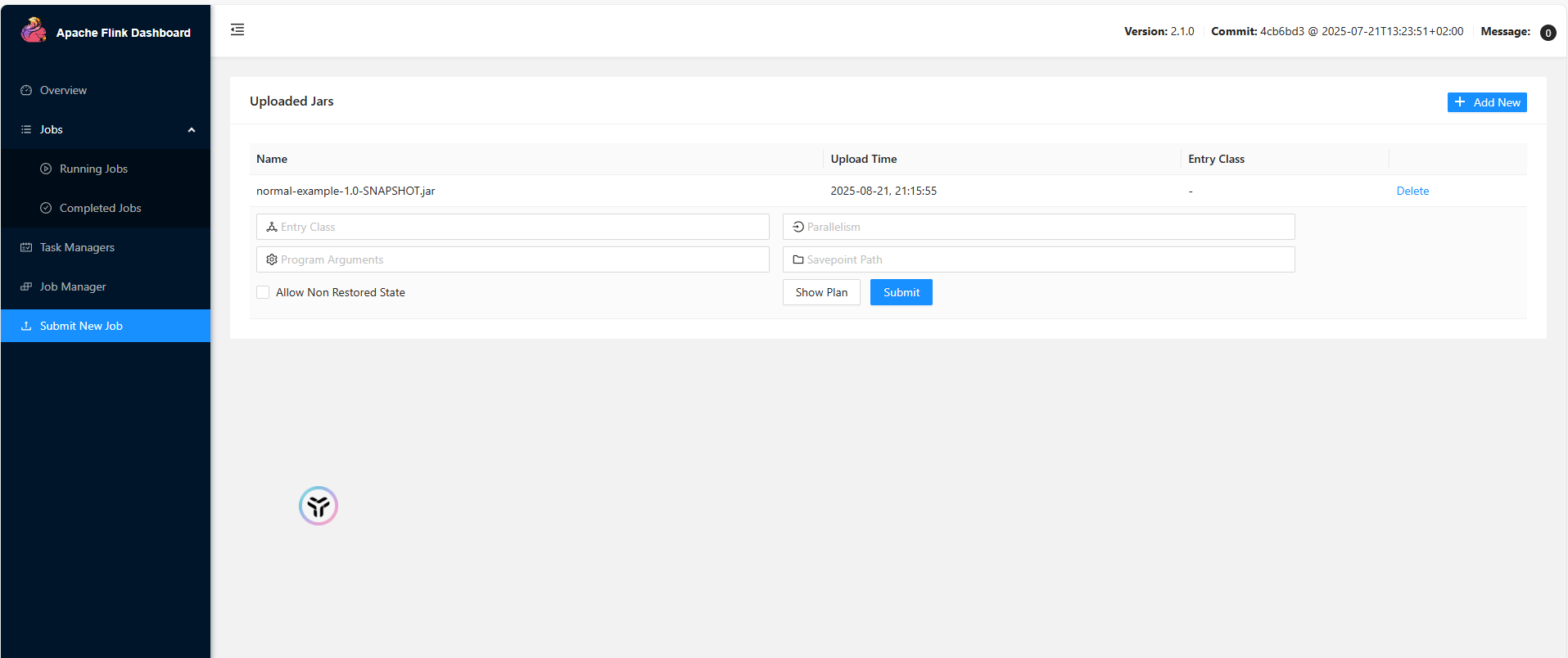
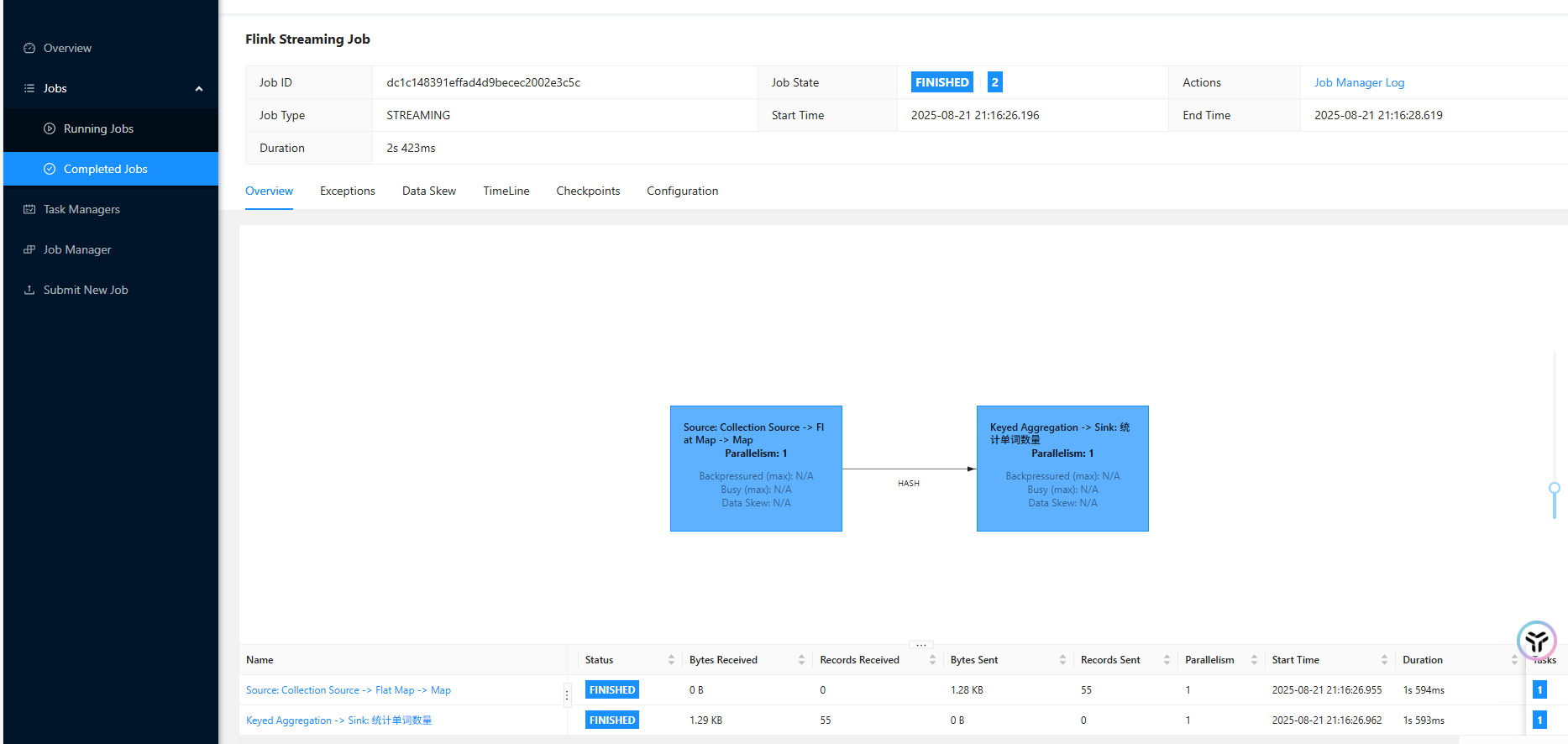
启动查看结果
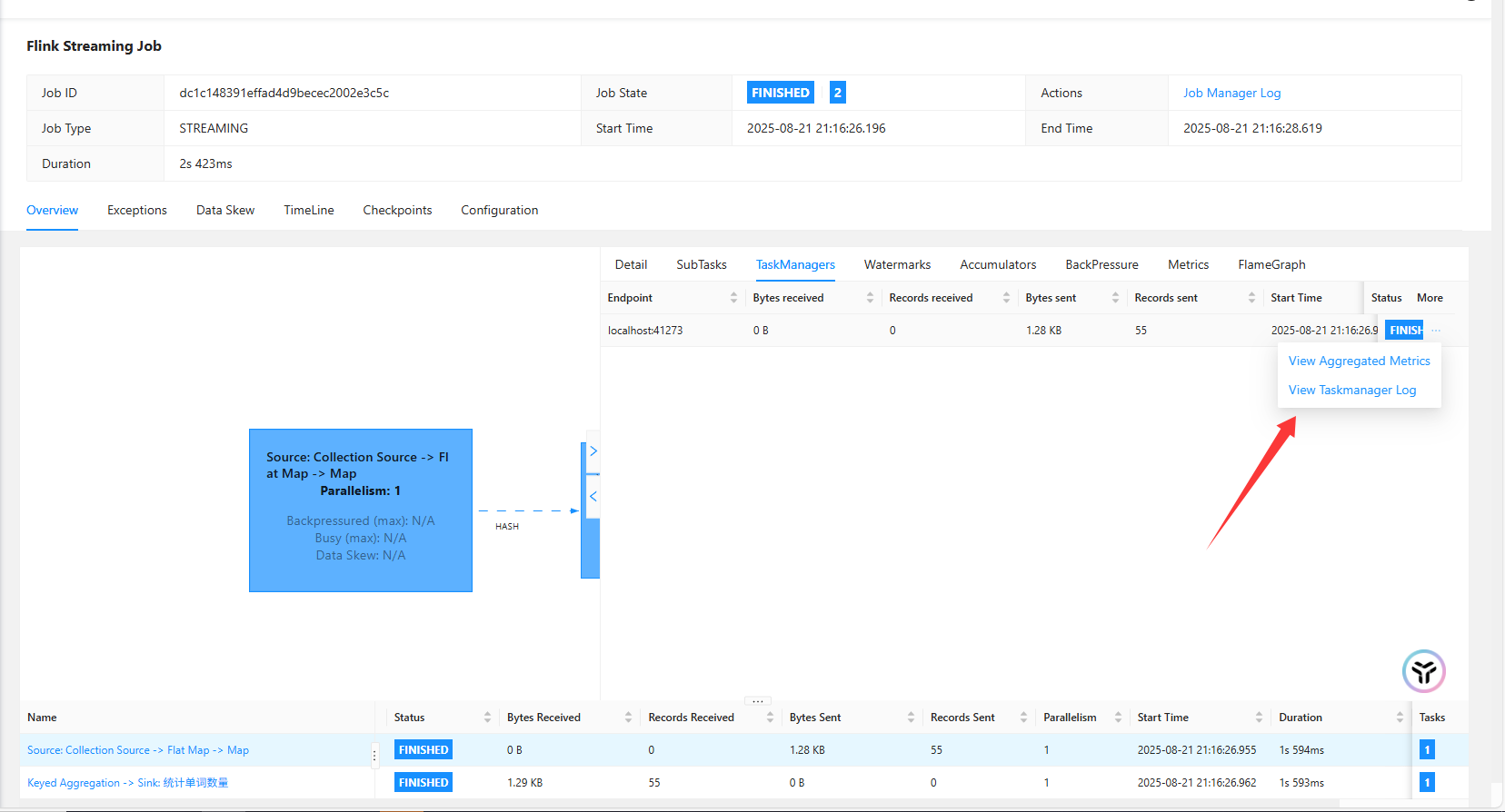
查看日志
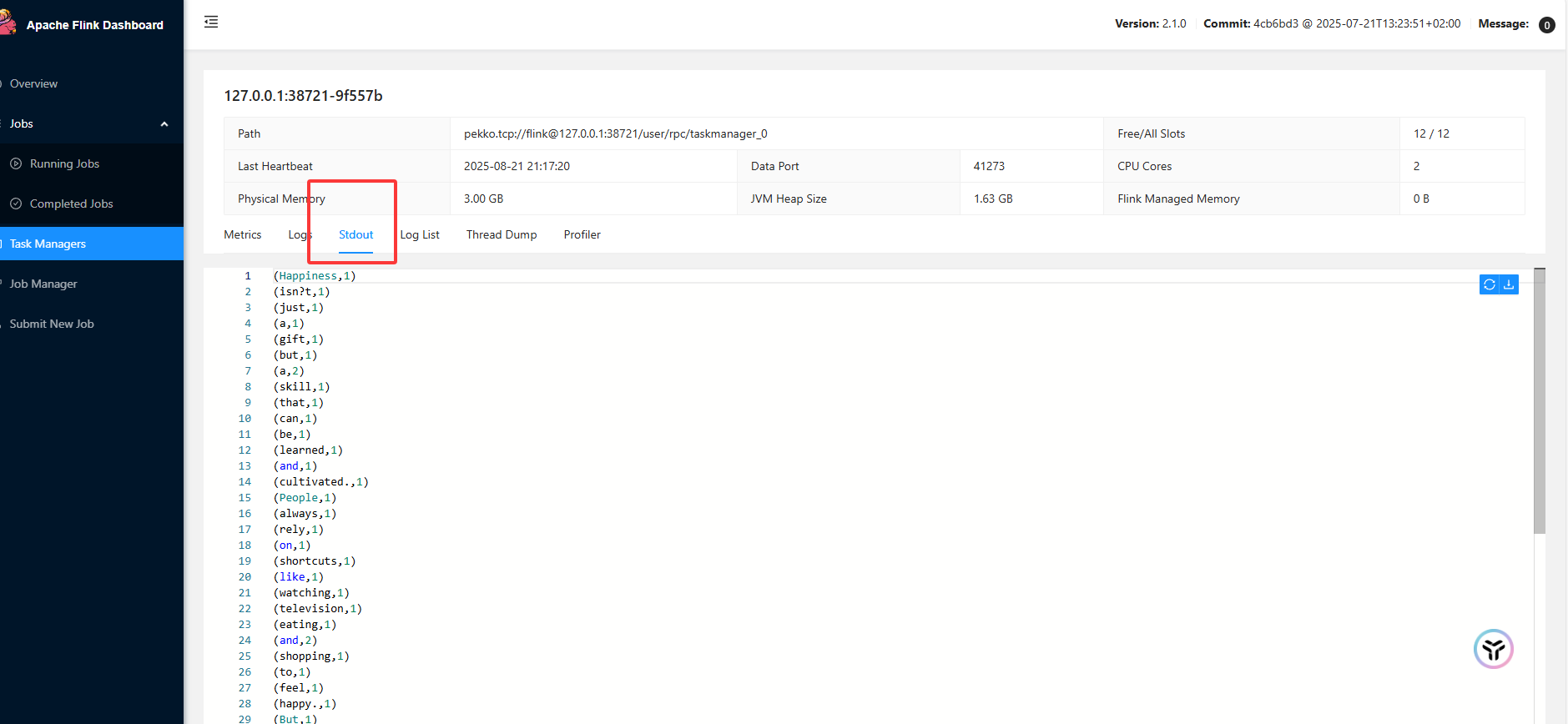
关于同一个单词输出多次问题
这是因为我们没有划分窗口,这样Flink在处理数据时,是基于每个数据项(分割出来的单词)进行一次计算并输出结果。 如下图所示, 第一个 数据a 进来,会统计当前有1个a 并输出 {count:1, word:a}, 后面再陆续有其它的a进来, 都会加到之前的sum结果上, 并且会输出当前这个数据项a 加完后的结果 {count: n, word:a }, 在输出结果上看感觉是a重复输出了。